Big Data’s Fourth Dimension – Time to Action

There is an important dimension in the Big Data space….the dimension of time, that few really understand.
I was walking with thought-leader and confidant, Rich Miller today. I have to give full credit to Rich for expanding the thinking on this “fourth dimension of Big Data” – the idea that your Big Data solution depends on the speed at which you need to analyze and act on the data.
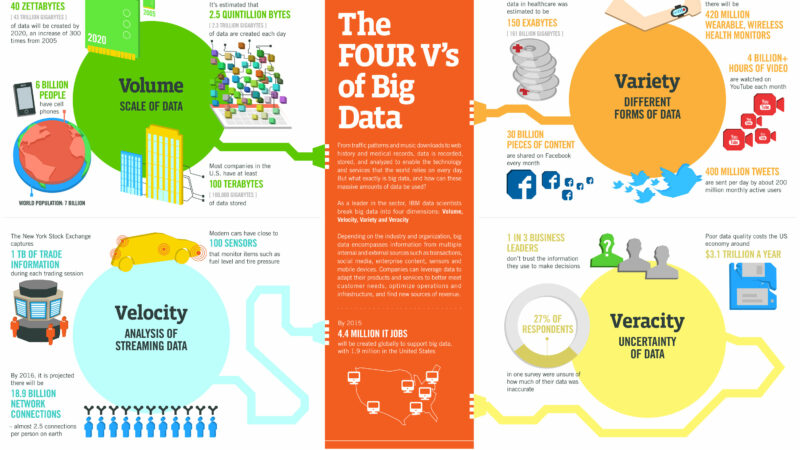
We all understand Gartner’s definition of Big Data with reference to Volume, Velocity, and Variety. But it’s the original fourth that I must confess, didn’t add much value for me…Gartner referred to it as “complexity” (meaning that “different standards, domain rules and even storage formats” can exist with each data type…making it more complex). I think others have found little value in using complexity in their analysis too, leading to new attributes of big data of their own. For example, I was reading Lori MacVittie’s definition of “data value” as the fourth ‘v’ in the Four V’s of Big Data.
I think that the three Vs have been more than adequate in defining Big Data.
So why do I, as others, propose a new “Fourth Dimension”?
It is based on my experience with virtually every customer on Big Data projects, as well as conversations with many business users on their future big data use-cases.
I argue that most, if not all, applications require data analytics to be applied and results acted upon in, generally, three categories of time:
I will attempt to identify some example use-cases where these definitions apply.
Real-Time In-Stream Analytics
 When I think of real-time, I immediately think of the financial services segment. Financial services (banks, hedge funds, etc.) use complex event processing tools to analyze data streams in real time and either trigger automated actions or alert people to patterns and trends. It’s well-known that traditional DBMSs, which need to store and index data before processing it, can hardly fulfill the requirements of timeliness coming from such domains.
When I think of real-time, I immediately think of the financial services segment. Financial services (banks, hedge funds, etc.) use complex event processing tools to analyze data streams in real time and either trigger automated actions or alert people to patterns and trends. It’s well-known that traditional DBMSs, which need to store and index data before processing it, can hardly fulfill the requirements of timeliness coming from such domains.
Real-time = data stream processing (connect to, analyze, and act upon) in <= 150 milliseconds.
This is clearly a scenario where you are processing small amounts of data (maybe in high velocity, and maybe many streams in parallel). Where the “Big” comes in with this scenario is the fact that these real-time data sources are aggregated into and feed very large resulting data stores.
As an example, algorithmic trading, also called automated trading, black-box trading, or algo trading, can leverage real-time Big Data technology coupled with proprietary algorithms for executing trading orders. Algorithmic trading is used by pension funds, mutual funds, and other buy-side traders. Sell side traders, such as market makers and some hedge funds, provide liquidity to the market, generating and executing orders automatically. A special class of algorithmic trading is “high-frequency trading” (HFT), in which computers make elaborate decisions to initiate orders based on information that is received electronically in real-time.
These financial CEP systems can be divided into three logical units: 1) data stream processing (the part of the system that receives data (e.g. quotes, news) from external sources), 2) decision analytics (the part of the system that applies the rules (e.e. determines whether to buy)), and execution (the part that translates the decision into action (e.g. a trade)). And believe it or not, with the wide use of social networks, some financial systems have begun to implement scanning or screening technologies to read posts of users extracting sentiment and influence for trading strategies.
In another use-case, I was working with a large retailer (bricks and clicks). The website traffic alone drove 500M web clickstream events, coupled with 28M or so online transactions, by 8M customers in a single month. Not only were the clickstreams feeding a large and growing unstructured Hadoop data store, they were being augmented by many other data streams (social, inventory, CRM, call center, in-store transactions, etc.). So you can begin to understand how “real-time” is an important part of Big Data.
Technologies that address real time stream processing requirements…in no particular order:
- S4
- AccelOps
- Storm
- HStreaming
- Streambase
- SQLStream
- InfoStreams
- OpenCQ
- NiagaraCQ
- TelegraphCQ
- Rapide
- Gemfire
- DistCEP
- CEDR
- Cayuga
- Raced
- Sase+
- Amit
- TESLA/T-Rex
- Progress Apama
- Tibco Business Events
- Esper
- Aleri/Coral8
- Oracle CEP
Real time stream processing applies to many use-cases outside of the financial services….from wireless sensor networks (telecom) to traffic management (transportation) to click-stream inspection (retail+).
Near Real-Time Ad-Hoc / Interactive Analytics
 This category addresses the need to have “as fast as disk” processing speeds, or “near real time”. This typically consists of NoSQL data stores which, generally, exhibit the following characteristics: schema-free, easy replication support, simple API, eventually consistent / BASE (not ACID), and supporting a huge amount of data. The term “NoSQL” also translates to mostly with “not only sql”.
This category addresses the need to have “as fast as disk” processing speeds, or “near real time”. This typically consists of NoSQL data stores which, generally, exhibit the following characteristics: schema-free, easy replication support, simple API, eventually consistent / BASE (not ACID), and supporting a huge amount of data. The term “NoSQL” also translates to mostly with “not only sql”.
Near real-time = fast ad-hoc and interactive queries (capture data, query data, and present) in seconds to minutes.
In this scenario we populate an interim data store with maybe a day’s, week’s, month’s, or at most a quarter’s worth of data which becomes either a rolling near-term view, and/or an aggregate of the real-time data feeds. In the end, you need something to appreciate what’s happening recently. You don’t need to ask big trending questions across quarters, year-over-year….yet. With this data service, you are asking questions like, “how’s my quarter trending in sales and why?”.
Some very fast big data query systems include:
- Hbase
- Impala
- Shark
- Drawntoscale
- MongoDB
- Cassandra
- Aerospike
- ElasticSearch
- Riak
- Redis
- CouchDB
- Gridgain
Generally speaking, there are over 150 NoSQL databases which can address your data management / data analytics which support lots of data with fast queries. The problem with this category of data stores is its large selection based on the type of data you are storing and querying (e.g. Key-Value, Big Table, Document, Graph…see the landscape). There are also over 20 NewSQL databases which are fast, scalable and ACID, supporting SQL.
Batch Analytics
 This category is predominantly supported by Hadoop (with scalable storage through HDFS and scalable computation through MapReduce). Hadoop is an open-source software framework that supports data-intensive distributed applications. Hadoop implements a computational paradigm with map/reduce, where the application analytics are divided into many small fragments of work, each of which may be executed or re-executed on any node in the cluster. It is very similar to the distributed architecture of Parsing Engines (PEs) and Access Module Processors (AMPs) in the linearly scalable Teradata system.
This category is predominantly supported by Hadoop (with scalable storage through HDFS and scalable computation through MapReduce). Hadoop is an open-source software framework that supports data-intensive distributed applications. Hadoop implements a computational paradigm with map/reduce, where the application analytics are divided into many small fragments of work, each of which may be executed or re-executed on any node in the cluster. It is very similar to the distributed architecture of Parsing Engines (PEs) and Access Module Processors (AMPs) in the linearly scalable Teradata system.
Batch = data processing (store, analyze, and report) in minutes to hours.
In this scenario, you are asking big-picture questions over longer history. You may want to cluster your customers based on purchase behavior during the Christmas season, but you can’t do so without 3 years of Christmas season data to draw some sort of idea. One thing is guaranteed though, this is a historical analysis. It’s data over a long period of time, across many dimensions, to determine how things cluster or should be classified. The output from analyzing data in batch feeds marketing campaign hypothesis which can be launched and measured for success in real-time and near real-time. The batch analytics feed the thesis and actions executed and observed by the other two data services.
And because of the fact that this involves as much data about the business you can capture and store, Hadoop is predicted to become the future Enterprise Data Warehouse (EDW), supporting petabyte-scale batch analytics via the following use-cases:
- Staging. The most frequent application is in support of the “T” in ETL (extract, transform, load), but where the data being extracted and transformed are in myriad unstructured, semistructured, and structured formats.
- Event analytics. Another key use is in doing petabyte-scale log processing of event data for call detail record analysis, behavioral analysis, social network analysis, IT optimization, clickstream sessionization, antifraud, signal intelligence, and security incident and event management. It essentially handles high-volume event processing in batch.
- Content analytics. This is an area where MapReduce modeling is its key competitive differentiator. Next best action, customer experience optimization, and social media analytics are every CRM professional’s hottest hot-button projects. They absolutely depend on plowing through streaming petabytes of customer intelligence from Twitter, Facebook, and the like and integrating it all with segmentation, churn, and other traditional data-mining models. MapReduce provides the abstraction layer for integrating content analytics with these more traditional forms of advanced analytics, and Hadoop is the platform for MapReduce modeling.
The key distributions of Hadoop include:
Applications Need Integrated Data Services
You give me any business, and I can not only give you use-cases in each of these categories (Real-time streaming analytics, near real-time ad-hoc analytics, and batch analytics), but I guarantee you that I can identify applications which require ALL three as part of an integrated data service.
I remember back when I was working with a bank in France. The DBA flew out to work with me on tuning the Teradata RDBMS they were using as the banks core data infrastructure. I gave the DBA advice on the tuning parameters and ran benchmarks to make sure all was right.
Then the next day, he would complain that his performance was terrible. I remember asking, “why is the performance bad? I ran the benchmarks myself.” I had printed out the performance numbers for a suite of decision support queries and posted them on my office wall. He then responded by saying, “Well, when I tuned for some of the OLTP queries we run, the DSS query performance becomes intolerable.”
Oh my god! This DBA was trying to run a mixed workload (DSS + OLTP) on the same database!!
Obviously, we would all love a SINGLE database which doesn’t require any ETL, where schemas could be deployed and changed within short timeframes with no impact on existing applications, and the database could execute real-time queries, complex ad-hoc queries in near real-time, and detailed decision support queries involving practically all data elements….oh, and that same SINGLE database can support thousands of users running those queries simultaneously!
Sorry, no such system exists. However, I do know of an integrated cloud service for Fortune 1000 companies which combines the best-in-class data infrastructure in each of these categories within the Big Data dimension of time.
I’m pleased to announce the Infochimps Enterprise Cloud – the first Big Data Cloud which deploys all three data services:
- real-time with our Data Delivery Services (DDS)
- ad-hoc / interactive analytics with our Data Management Services, and
- batch analytics with our Elastic Cloud Hadoop Services
…..and all tied together in public as well as virtual private, and private cloud offerings (your private data, your private cloud). Do you want to convert data into revenue in 30 days?
Related posts:
Era of Analytic Applications – Part 1
Era of Analytic Applications – Part 2
The Data Era – Moving from 1.0 to 2.0



{kind=link}
5 thoughts on “Big Data’s Fourth Dimension – Time to Action”
Comments are closed.