The Data Era – Moving from 1.0 to 2.0
Do you think they truly under stood just how fast the data infrastructure marketplace was going to change?
That is the question that comes to mind when I think about Donald Feinberg and Mark Beyer at Gartner who, last year, wrote about how the data warehouse market is undergoing a transformation. Did they, or anyone for that matter, understand the significant change underway in the data center? I describe it as Big Data 1.0 versus Big Data 2.0.
Big Data 1.0
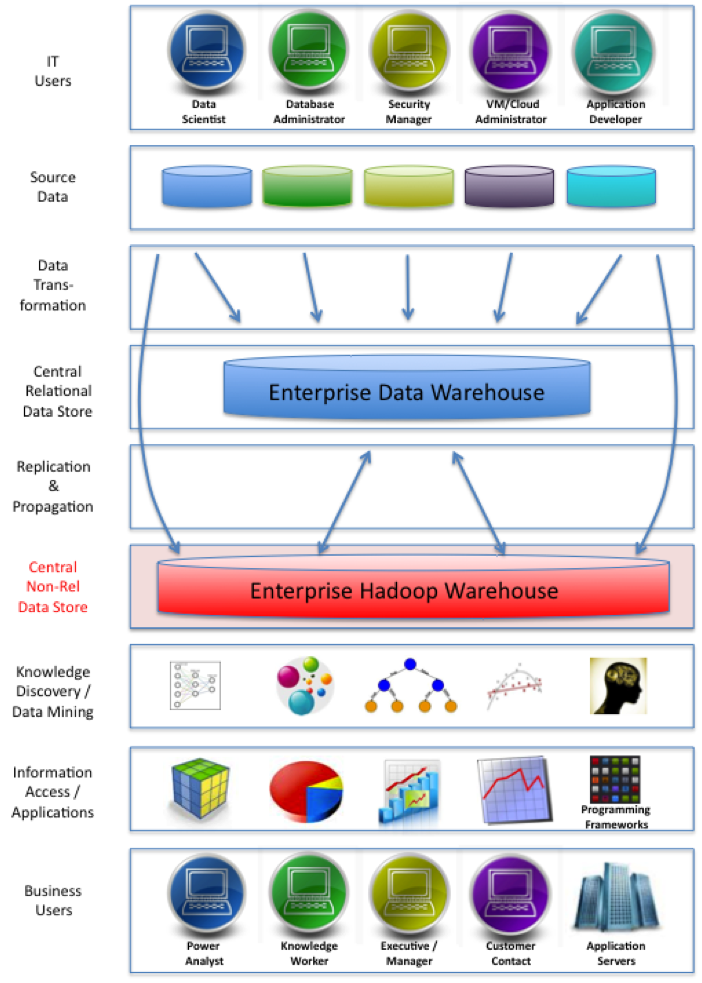
I was recently talking to friends at one of our largest banks about their Big Data projects under way. In less than one year, their Hadoop cluster has already far exceeded their Teradata enterprise data warehouse in size.
Is that a surprise? Not really. When you think about it, a traditionally large data warehouse is always in the terabytes, not petabytes (well, unless you are eBay).
With the current “Enterprise Data Warehouse” (EDW) framework (shown here) we will always see the high-value structured data in the well-hardened, highly available and secure EDW RDBMS (aka Teradata).
In fact, Gartner defines a large EDW starting at 20TB. This is why I’ve held back from making comments like, “Teradata should be renamed to Yottadata.” After all, it is my “alma mater” after having spent 10 years learning Big Data 1.0 there. I highly respect the Teradata technology and more importantly the people.
Big Data 2.0
So with over two zettabytes of information being generated in 2012 alone, we can expect more “Big Data” systems to be stood up, new breakthroughs in large dataset analytics, and many more data-centric applications being developed for businesses.
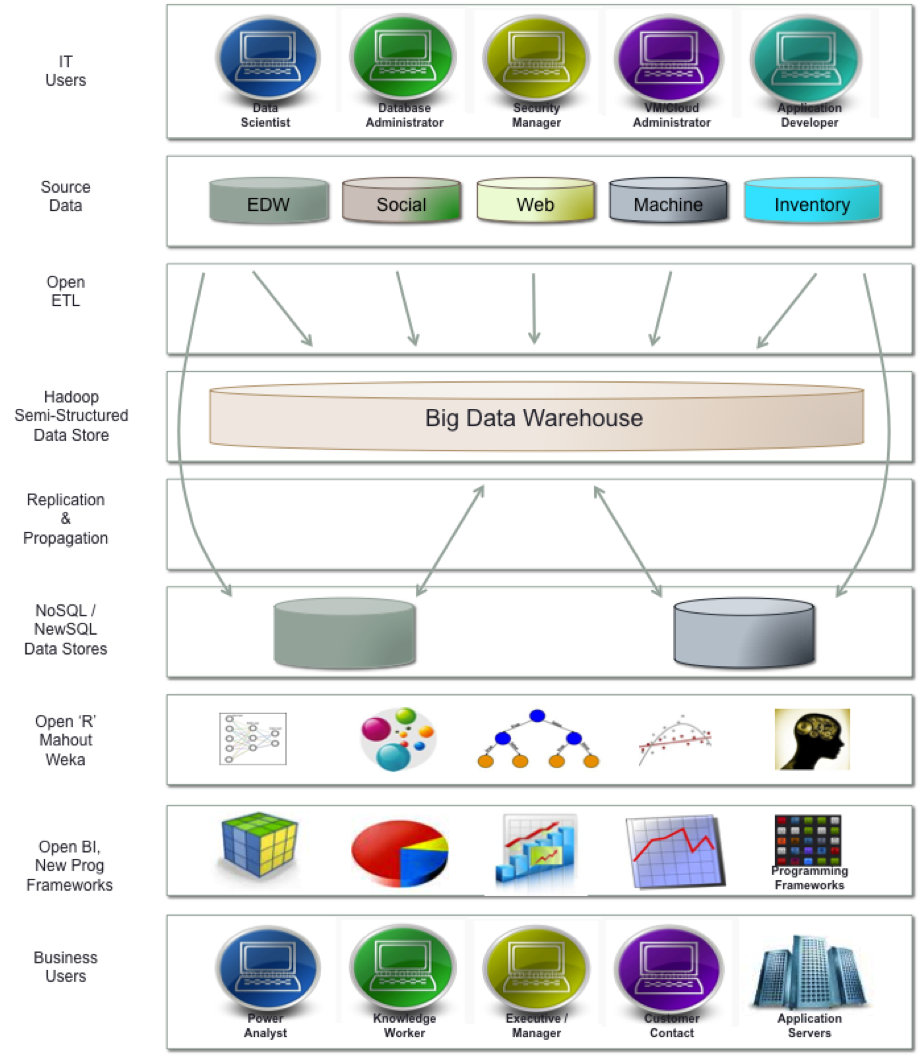
However, many of the “new systems” will be driven by “Big Data 2.0” technology. The enterprise data warehouse framework itself doesn’t change much. However, there are many, many new players – mostly open source, who have entered the scene.
Examples include:
* Talend for ETL
* Cloudera, Hortonworks, MapR for Hadoop
* SymmetricDS for replication
* Storm, S4, for real-time stream processing
* Hbase, Cassandra, Redis, Riak, Elastic Search, etc. for NoSQL / NewSQL data stores
* ’R’, Mahout, Weka, etc. for machine learning / analytics
* Tableau, Jaspersoft, Pentaho, Datameer, Karmasphere, etc. for BI
These are so many new and disruptive technologies, each contributing to the evolution of the enterprise’s data infrastructure.
I haven’t mentioned one of the more controversial statements made in the adjacent graphic – Teradata is becoming a source along side the new pool of unstructured data. Both the new and the old data are being aggregated into the “Big Data Warehouse”.
We may also be seeing much of what Hadoop does in ETL feeding back into the EDW. But I suspect that this will become less significant as compared to the new analytics architecture with Hadoop + NoSQL/NewSQL data stores at the core of the framework – especially as this new architecture becomes more hardened and enterprise class.
Infochimps’ Big Data Warehouse Framework
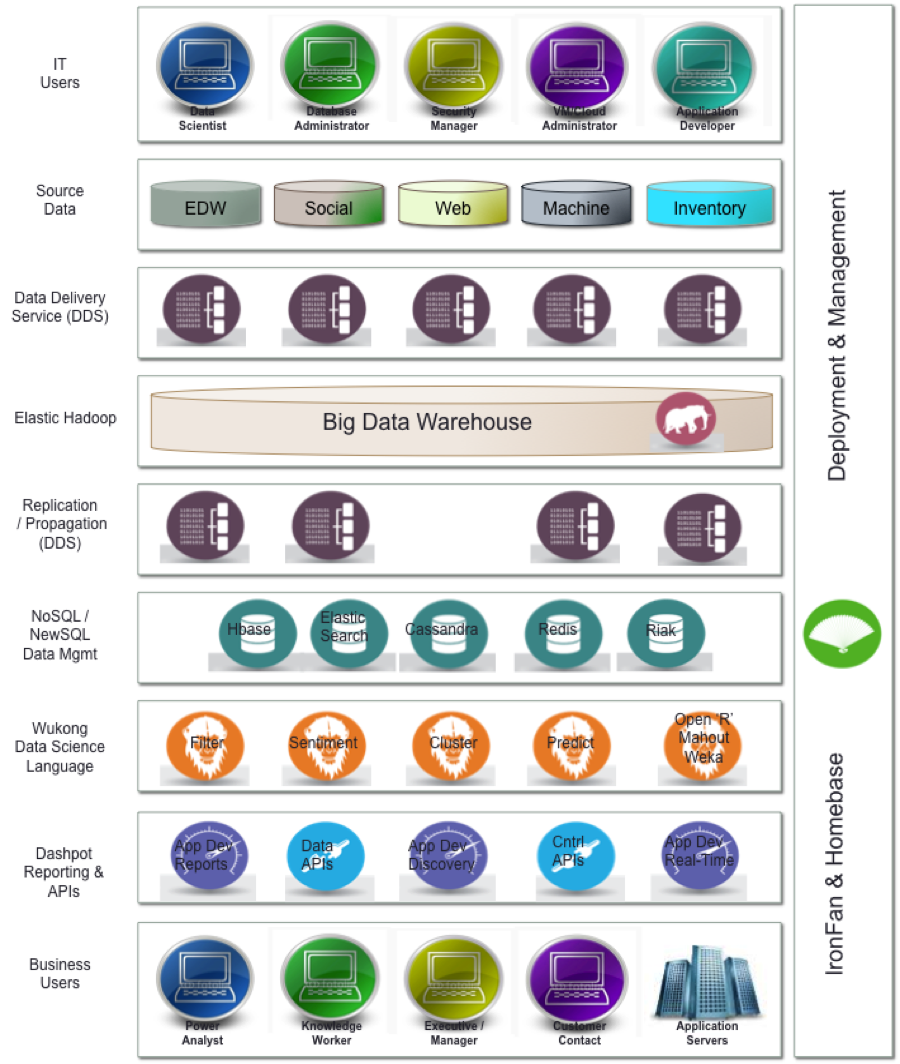
This leads us to why I’m much more than a fan of Infochimps (see disclosure below) and why I believe the company is so well positioned to make a significant impact within the marketplace.
By leveraging four years of experience and technology development in cloud-based big data infrastructure, the company is now offering a suite of products that contribute to each part of Big Data Warehouse Framework for enterprise customers.
DDS: With Infochimps’ Data Delivery Services (DDS), our customer’s application developers do not rely on sophisticated ETL tools. But rather, they can manipulate data streams of any volume or velocity using DDS through a simple developer-friendly language, referred to as Wukong. Wukong turns application developers into data scientists.
Ingress and egress can be handled directly by the application developer, uniquely bridging the gap between them and their data.
Wukong: Wukong is much more than a data-centric domain specific language (DSL). With standardized connectors to analytics from ‘R’, Mahout, Weka, and others, not only is data manipulation made easy, integration of sophisticated analytics with the most complicated data sources is also made easy.
Hadoop & NoSQL/NewSQL Data Stores: At the center of the framework, is not only an elastic and cloud-based Hadoop stack, but a selection of NoSQL/NewSQL data stores as well. This uniquely positions Infochimps to address both decision support-like workloads, which are complex and batch in nature, with OLTP or more real-time workloads as well. The complexities of standing up, configuring, scaling, and managing these data stores is all automated.
Dashpot: The application developer is typically left out with many of the business intelligence tools offered today. This is because most tools are extremely powerful and built for special groups of business users / analysts. Infochimps has taken a slightly different approach, staying focused on the application developer. Dashpot is a reporting and analytics dashboard which was built for the developer – enabling quick iteration and insights into the data, prior to production and prior to the deployment of more sophisticated BI tools.
Ironfan and Homebase: As the underpinning of the Infochimps solution, Ironfan and Homebase are the two solutions which essentially abstract any and all hardware and software deployment, configuration, and management. Ironfan is used to deploy the entire system into production. Homebase is used by application developers to create their end-to-end data flows and applications locally on their laptops or desktops before they are deployed into QA, staging, and/or production.
All-in-all Infochimps has taken a very innovative approach to enabling application developers with Big Data 2.0 technologies in a way that is not only comprehensive, but fast, simple, extensible, and safe.
Our vision for Infochimps leverages the power of Big Data, Cloud Computing, Open Source, and Platform as a Service – all extremely disruptive technology forces. We’re excited to be helping our customers address their mission critical questions, with high impact answers. And I personally look forward to executing on our vision to provide the simplest yet most powerful cloud-based and completely managed big data service for our enterprise customers.
Disclosure: I’ve just taken the role of CEO at Infochimps. I’m really looking forward to working with Joe, Flip, Dhruv, and the team.
Related posts:
Era of Analytic Applications – Part 1
Era of Analytic Applications – Part 2
Big Data’s Fourth Dimension – Time



{kind=link}
One thought on “The Data Era – Moving from 1.0 to 2.0”
Comments are closed.