‘A Chink in Amazon’s Armor’ – We want 5 Nines!
“We can confirm connectivity errors impacting EC2 instances and increased latencies impacting EBS (Elastic Block Storage) volumes in multiple availability zones in the US-EAST-1 region,” Amazon said Thursday on its service health dashboard.
The US-EAST-1 region, based in northern Virginia, is one of several Amazon regions around the world. There’s another one in northern California. Amazon started reporting troubles at 4:41 a.m. Eastern time. By 1:26 p.m., Amazon said it is “now seeing significantly reduced failures and latencies,” but that problems were still ongoing. Amazon blamed a “networking event” that “triggered a large amount of re-mirroring” of storage volume, creating a capacity shortage.

It’s no secret that Amazon’s SLA provides for 99.95% uptime. That only provides you protection from 4.38 hours or more of impact to your business. Even then, as the SLA states, your retribution is receiving a 10% credit to your bill.
If the Annual Uptime Percentage for a customer drops below 99.95% for the Service Year, that customer is eligible to receive a Service Credit equal to 10% of their bill (excluding one-time payments made for Reserved Instances) for the Eligible Credit Period. To file a claim, a customer does not have to have wait 365 days from the day they started using the service or 365 days from their last successful claim. A customer can file a claim any time their Annual Uptime Percentage over the trailing 365 days drops below 99.95%.
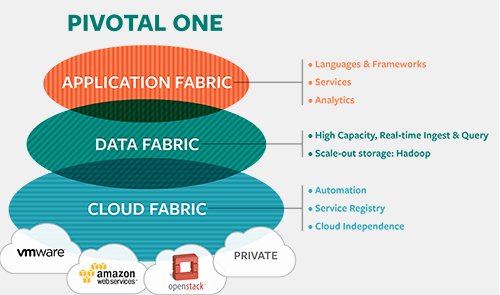
How does one achieve the 5 Nines of availability? Well, you simply need to combine data replication and application failover to your already complex application architecture……across Amazon availability zones (geographically dispersed) or across cloud providers altogether.
 We toyed with this solution using sophisticated technology made easy at SIOS, which combined three technologies – cloud deployment/management from Skydera, Data Replication, and Application Failover (HA) software. Jeff Barr and I talked about it at length as a way to increase HA and provide DR capabilities within Amazon.
We toyed with this solution using sophisticated technology made easy at SIOS, which combined three technologies – cloud deployment/management from Skydera, Data Replication, and Application Failover (HA) software. Jeff Barr and I talked about it at length as a way to increase HA and provide DR capabilities within Amazon.
I believed it was a way to reach 99.999% availability within Amazon (that’s 5 minutes of downtime per year). We actually deployed some mission critical applications like SugarCRM and a financial trading application built on WebSphere using failover from AWS regions in the US and the EU.

{kind=link}