What’s BIG DATA and BIG ANALYTICS?
Big Data

True or False: It’s possible to create an exabyte RDBMS cluster?
One of my first jobs out of college involved working with a handful of elite engineers tucked away far from corporate.
My job….to advance what was known as the Ynet. The Ynet provided for communication among all processors in all models of the DBC 1012 since the architecture was first conceived by Jack Shemer and the Teradata team in the early 1980’s. It always operated in a broadcast (one-to-all communication) mode and the two Ynets in a system had a total bandwidth of 12 MBPS. This architecture supported systems with 200-300 processor nodes at the time.
Our project, the BYNET, involved architecting the next-generation Ynet that allowed all processor module assemblies (PMA) to communicate with each other in either a point-to-point or broadcast fashion. Each PMA was connected to two networks (for redundancy). The network itself was constructed from a modular switch node building block – a 8×8 crossbar that can connect any of its eight input ports to its eight output ports simultaneously using a circuit switching approach.
According to Tom Fastner, Sr. MTS – APD Architecture for eBay and responsible for their Teradata platform:
Our 256 node system has a total of about 25 TB RAM, 36 PB disk, and 4608 AMPs (data Access Module Processors). It is a cluster of 1,680 2x6core CPUs, 72x 2 TB drives, 96 GB RAM; 18 AMPs per node; there is 1 active and 1 hot standby node.
The largest table is 1.5 PB compressed (about 8 PB of raw uncompressed data).
Today a BYNET-enabled system supports up to 4096 processor module assemblies. I figure that with processor node and disk improvements over the next 5 years, a fully configured system from Teradata could support a single database of greater than an exabyte. Let me repeat….
True: It’s possible to create a single exabyte relational database cluster
That’s a lot of data. Would this classify as Big Data? Yes. But it’s still only a drop in the “digital universe” bucket.

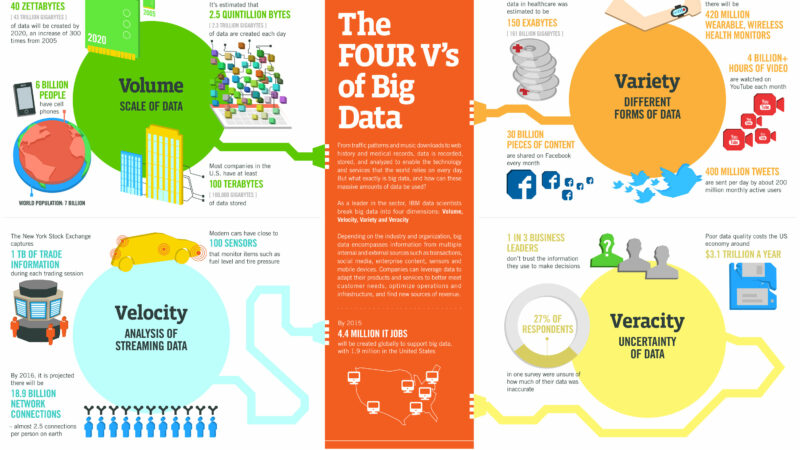
In 2011 alone, the amount of information created and replicated will surpass 1.8 zettabytes (1.8 trillion gigabytes) – growing by a factor of 9 in just five years, and more than doubling every two years (IDC 2011 Digital Universe Study). The digital universe will grow from 1.2 Zettabytes in 2010 to 35.2 Zettabytes in 2020 (44x).
While 75% of the information in the digital universe is generated by individuals, the amount of information individuals create themselves – writing documents, taking pictures, creating videos, etc. – is far less than the amount of information being created about them. Data about data, or metadata, is growing twice as fast as the digital universe as a whole (e.g. facial recognition routines that help tag Facebook photos).
The most important fact is that 90% of the digital universe is unstructured data (versus the structured domain of RDBMS). New capture, search, discovery, and analysis tools are now being developed to help organizations gain insights (knowledge) from this exploding source of data.
Big data describes a new generation of technologies and architectures, designed to economically extract value from very large volumes of a wide variety of data, by enabling high-velocity capture, discovery, and analysis.
Big Data can include transactional data, enterprise data warehouse data, metadata, and other data residing in files everywhere (I recently referred to this as the “Virtual Data Center”, a term that has been used before).
With social media offerings such as Facebook, Twitter, Linkedin, and Foursquare we’re introduced to the newest data sources, with new high-velocity requirements associated with capture and analysis, as well as results/predictive reporting.
Big Analytics
 Business intelligence tools increasingly are dealing with real-time data, whether it’s charging auto insurance premiums based on where people drive, routing power through the intelligent grid, or changing marketing messages on the fly based on social networking responses.
Business intelligence tools increasingly are dealing with real-time data, whether it’s charging auto insurance premiums based on where people drive, routing power through the intelligent grid, or changing marketing messages on the fly based on social networking responses.
The advent of real-time analytics will allow the processing of information in real time to enable instantaneous decision-making (or that’s at least the promise).
Thanks to various Hadoop optimizations, complementary technologies, and advanced algorithms, real-time analytics are becoming a real possibility. The goal for everyone seeking real-time analytics is to have their services act immediately — and intelligently — on information as it streams into the system.
Companies like Hstreaming promise real-time analytics on Hadoop distributions. 33Across, has a marketing platform that lets companies target potential customers based on those companies’ social graphs. They constantly re-score the brand graph to understand who are the best targets for that ad right now. In order to do this, 33Across maintains a “massive Hadoop implementation” complemented by machine-learning and predictive-analytics algorithms that it has developed in-house.
Other examples of “Big Analytics” includes Google’s BigQuery Service which is based on Dremel. It’s essentially an OLAP tool for very large data sets.
Is this idea of Big Analytics just hype, or is there real demand? A new study by research house Ovum has revealed that almost half of organisations in North America, Europe and Asia-Pacific plan to invest in Big Data analytics in the near future (meaning within the next 12 months).
So what are some of the killer apps? Real-time Big Analytics application use-cases?



{kind=link}
Informative article Jim! You mention Hadoop and some alternatives. The HPCC Systems platform is among them for tackling Big Data problems. Unlike Hadoop distributions which have only been available since 2009, HPCC is a mature platform, and provides for a data delivery engine together with a data transformation and linking system equivalent to Hadoop. The main advantages over other alternatives are the real-time delivery of data queries and the extremely powerful ECL language programming model. More at http://hpccsystems.com
Great perspectives Jim ! Keep them coming …